对博客 Zed Decoded: Rope & SumTree 的翻译
同系列翻译: Zed's blog
进入翻译部分:
开篇
这是 Zed-Decoded 系列的第二篇文章,我们的博客与视频将更深入地探讨: Zed 是如何构建的
我与 Zed 的三位联合创始人: Nathan, Max, Antonio 一起讨论了作为 Zed 核心的数据结构:rope
(youtube 上的配套视频: 传送门)
我一直不太理解 Zed 的 rope 是如何实现的, 以及其带来了什么好处, 所以我问了他们 (这么多年来, 他们一直在写关于 rope 的代码)
事实证明, Zed 中的 rope 并非传统意义上的 rope, 这让人形象深刻
但首先, 什么是 rope?
为何不用字符串?
文本编辑器必须做的一件最重要的事情,就是去以某种方式表示文本(text), 你希望在编辑器中打开文件时, 可以浏览并编辑其中的内容
为此, 编辑器必须将文件的内容加载到内存中, 用户不该盯着磁盘上原始的字节, 且每个编辑更改的操作不应该都立刻保存在磁盘中
所以问题来了: 如何在内存中表示文本呢?
我天真无比的第一个想法就是使用字符串(String), Good old string, 我们刚刚开始编程时最好的朋友!
为什么不用它呢? 我们一直这样在内存中表示文本, 这不是个糟糕的选择, 对吧?
嘿, 我敢打赌用 String 可以走很远, 但其依然存在一些问题以至于并非最佳选项, 希望程序处理大文本时保持高效与迅速相应的话更是如此
字符串的问题
String 通常会分配为连续的内存块, 这可能导致编辑效率变得低下
假设有一个存储着 20k 行的字符串, 你想在该字符串的中间插入一个单词
为此, 你必须在字符串中间为新单词腾出空间, 使得最后仍然能得到一个分配为连续内存块的字符串
而为了腾出空间, 你又必须移动新插入的单词之后的所有文本, 移动意味着会分配内存, 最坏情况下必须移动所有内容
对, 所有的, 所有的 20k 行, 仅仅是为了腾出存储新单词需要的空间
再比如, 当你想删除一个单词时, 你不能只是在字符串上戳一个洞, 因为这意味着它不再是一个字符串(连续分配的内存块)
相反, 你必须移动除了待删除单词之外的所有字符, 使得最后会再次得到一个单独的, 连续的, 不包括删除单词的内存块
再处理小文本时这些都不是问题, 我们每天都在做类似的操作, 对吧? 是的, 但大多数时候我们谈论的是较小的字符串
当你处理大文本时, 或者进行大量编辑时(甚至可能: hello! multiple cursors!), 这些都会成为问题
注意, 这甚至没有触及文本编辑器对文本的表示可能具有的所有其他要求
比如导航(Navigation), 当用户想跳转到第 523 行时, 该怎么办?
如果你手上只有一个表示了这些文本的字符串, 则必须逐个字符进行遍历, 并计算其中的换行符, 以找出 "第523行" 的位置
然后, 如果用户按向下箭头 10 次以向下移动 10 行, 并希望最终处于同一列, 该怎么办?
你必须再次开始计算字符串中的换行符, 然后再最后一个换行符后找到正确的偏移量(offset), 处理 "处于同一列" 的要求
再比如, 假设你想在编辑器的底部绘制一个水平滚动条, 想知道滚动滑块的大小以便于绘制, 你必须知道文件中最长的一行有多长
同样的事情, 你必须遍历字符串并计算行数, 这次还要追踪每行的长度
或者再来个例子, 如果要加载到编辑器中的文本文件大于 1GB, 而 某些语言 用来实现编辑器, 最大只能表示 1GB 的字符串, 该怎么办?
你可能会说, "1GB的字符串对每个人来说都应该足够了", 但这只能告诉我, 你还没有与足够多的用户交流过
哈, 开个玩笑而已, 我认为我们已经确定, 字符串(String)并非在文本编辑器中表示文本的最佳解决方案
那么我们还能用什么呢?
比字符串更好的是?
如果你真的很喜欢字符串, 你可能会想, 简单, multiple strings! 哦, 你离答案并非那么远
一些编辑器确实将文本表示为行数组, 每行都用一个字符串表示
vscode 的 Monaco 编辑器以这种方式工作了很长一段时间: previous-text-buffer-data-structure
但字符串数组仍然会受到与单个字符串相同问题的困扰, 过多的内存消耗与性能问题迫使 vscode 团队寻找更好的办法
幸运的是, 确实存在比 String 更好的东西
构建文本编辑器的人们很久以前就意识到字符串并非完成这项工作的最佳工具, 并提出了其他的数据结构来表示文本
据我所知, 最受欢迎的几位是: gap buffer, piece table, 与 rope
它们各有利弊, 我并不会在这里详细比较它们, 知道它们都明显优于字符串就足够了
不同编辑器在权衡利弊时做出了不同决定(优化以更适合自己): emacs/gap-buffer, vscode/piece-table, vim/its-own-tree, helix/rope
Zed 也使用了 rope, 现在让我们看看它比字符串多出了哪些优势
Ropes
以下是 维基百科(Wikipedia) 对 rope 的定义与解释:
A rope is a type of binary tree where each leaf (end node) holds a string and a length (also known as a "weight"), and each node further up the tree holds the sum of the lengths of all the leaves in its left subtree.
rope 是一种二叉树, 其每个叶子节点包含一个 string 与一个 length(也被叫作 weight), 树上每个节点都包含其左子树中所有叶子的 length
rope 并非连续内存块, 而是一棵树, 其叶子是它所代表的文本的字符(characters) A rope representing
以下是文本 "This is a rope" 在 rope 中的样子: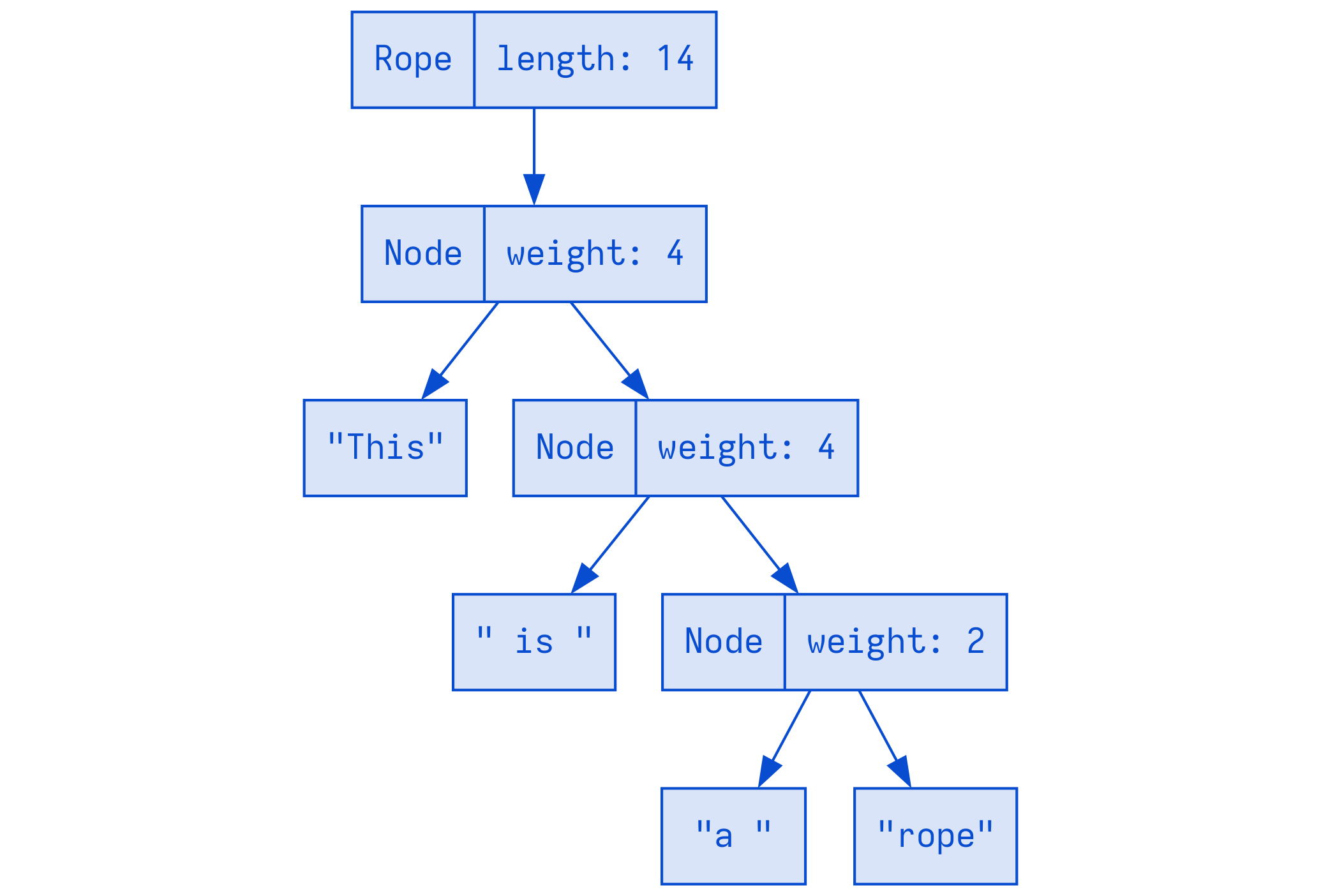
This is a rope
你现在可能认为这比字符串要复杂得多......你是对的, 确实如此
但在许多情况下, rope 存在一个战胜 string 的关键部分: 叶子节点(leaves), 比如 "This", " is ", "a ", "rope" 基本是不可变的
你不是修改字符串, 而是修改树, 无需在字符串中戳孔并在内存中移动它的一部分, 而是修改树以获取新字符串
到目前为止, 作为程序员, 我们已经弄清楚了如何有效地利用树
让我们再次回到上面的例子: 删除文本中某个位置的单词
使用 string 时, 我们必须重新分配单词后面的所有文本(可能是整个字符串)
使用 rope 时, 找到要删除的单词的开始与结束位置, 然后在这两个位置拆分树, 这样就有四棵树
扔掉中间的两颗(只包含待删除的单词), 连接另外两颗树, 然后重新平衡树
是的, 这听起来确实很麻烦, 且确实需要在后台进行一些算法处理, 但与字符串相比, 内存与性能的改进会非常明显
我们无需在内存中移动内容, 只需要更新几个指针, 对于像 "This is a rope" 这样的短文本来说有点愚蠢, 但当文本很大时会节省很多时间
这听起来有点抽象, 所以让我们来看看 Zed 是如何实现 rope 的
Zed的实现
Zed 在自己的 crate 中有自己的实现: rope
(自己实现而不是使用库的原因之一是, 当创始人们在 2017 年为 Zed 奠定基础时有很多库不存在)
在 rope 这个库中的主要类型是 Rope, 以下是使用方法:
let mut rope = new;
rope.push;
到目前为止, 它与 String 非常相似, 现在假设我们有两个 Rope:
let mut rope1 = new;
rope1.push;
let mut rope2 = new;
rope2.push;
如果我们想连接它们, 我们要做的是:
rope1.append;
assert_eq!;
对 rope1.append 的调用通过构建包含这两颗树的新树来进行连接, 这只不过是更新了几个指针而已
将其与字符串进行比较, 如果你连接两个字符串, 则必须在内存中移动其中至少一个, 以便于形成一个连续的块
通常你必须移动它们, 因为第一个字符串之后没有足够的空间
同样, 这个例子中的文本短得令人发笑, 如果有人想在一个文件中拥有 25k 行 SQLite amalgamation 的 10 份副本该怎么办?
现在再看看如何替换一个单词:
// Construct a rope
let mut rope = new;
rope.push;
// Replace characters 4 to 10 (0-indexed) with "guinness".
rope.replace;
assert_eq!;
在幕后发生了:
replace()首先将会创建一个新的 rope, 它包含了原先 rope 第 5 个字符(c)之前的所有节点- 新的文本
guinness被 appended 到了新的 rope 上 - 原先 rope 的剩下部分(第 11 个字符之后的所有内容), 将会被 appended 到新的 rope 上
let mut rope = new;
rope.push;
rope.replace;
即使在处理大量文本时, 这些操作也非常快速, 因为树中的大多数节点都可以重用, 只需要重新连起来(rewired)即可
但对于被删除的单词 "coffee" 会怎么样呢? 一旦没有其他节点再引用(reference)这些字符, 包含这些字符的叶节点就会被自动清理
这就是 rope 中不可变的叶子节点的作用: 当一个 rope 被改变, 或从旧的构造新的, 或合并两个 rope 时, 本质改变的都是对叶节点的引用
并且这些引用会被计数: 一旦某个节点不再被引用, 它就会被清理
再准确点, 从技术上来讲: 叶节点. 即包含实际文本的节点, 在 zed 的 rope 实现中并不是完全不可变的
节点具有最大长度, 当足够短的文本将被添加到最后的叶节点时, 若添加后仍不超出其最大长度, 则节点就自然会被更改, 直接将文本添加到其中
不过, 从概念层面上来讲, 你可以将 rope 视作 持久数据结构, 且将其节点视作树中引用计数的不可变节点
这就是为什么它比字符串好的原因, 并让我们回到上面跳过的一个问题: 为什么 Zed 选择 rope 而不是其他数据结构?
为何Zed使用rope?
Zed 的目标是成为高性能的代码编辑器
如我们所见, 字符串不会获得高性能, 那么用什么来替代呢? gap-buffer? piece-table? rope?
这里没有一个明显优于其他的最佳最好的方案, 这一切都取决于具体需求以及你愿意为满足这些需求做出的权衡
也许你听说过 gap-buffer 比 rope 更快更容易理解, 亦或者 piece-table 更加优雅...... 这可能是真的, 是的, 但这仍然不意味着它们是所谓的 "明显的最佳方案"
下面是 ropey(rust 中流行的 rope 实现)的作者写的, 关于 rope 与 gap-buffer 间的性能权衡:
Ropes make a different performance trade-off, being a sort of "jack of all trades". They're not amazing at anything, but they're always solidly good with O(log N) performance. They're not the best choice for an editor that only supports local editing patterns, since they leave a lot of performance on the table compared to gap buffers in that case (again, even for huge documents). But for an editor that encourages non-localized edits, or just wants flexibility in that regard, they're a great choice because they always have good performance, whereas gap buffers degrade poorly with unfavorable editing patterns.
rope 是一种在性能上做出了不同权衡的 "万事通". 它们在任何事情上都无法达到 "令人惊叹" 的程度, 但总是具有 O(log N)的良好性能. 对于仅支持本地编辑模式的编辑器来说, 其并非最佳选择, 因为在这种情况下相比 gap-buffer 会降低许多性能(即使是大型文档). 但对于鼓励非本地化编辑或只是希望在这方面具有灵活性的编辑器来讲, rope 是个很好的选择, 因为它们始终具有良好的性能, 而 gap-buffer 在编辑模式不利的情况下, 性能下降会非常糟糕
简单来说, rope在任何事情上都无法达到令人惊叹的程度, 但总体来说还是很不错的, 这取决于你想做什么, 或者希望你的编辑器能够做什么
比如, 如果你真的想利用 CPU 中的所有内核怎么办? 在 Text showdown: Gap Buffers vs Ropes中, 末尾提到了并发性:
Ropes have other benefits besides good performance. Both Crop and Ropey [note: both are rope implementations in Rust] support concurrent access from multiple threads. This lets you take snapshots to do asynchronous saves, backups, or multi-user edits. This isn't something you could easily do with a gap buffer.
除了性能良好, rope 还有其他好处. 无论是 crop 还是 ropey(两者都是 rust 中流行的实现) 都支持来自多个线程的并发访问. 这允许你进行快照以便于执行异步保存, 备份, 或者多用户编辑. 这不是你可以用 gap-buffer 轻松完成的事情
在我们的 配套视频 中, 你可以听到 Max 对这一段的评价: "确实, 这比其他任何事都重要"
其中, "这" 指的就是并发访问, 快照, 多用户编辑, 异步操作
换句话说, 并发访问 buffer 的文本是 Zed 的硬性要求, 这就是为什么 rope 最终成为首选的原因
下面是一个实例, 说明对文本的并发访问在 Zed 中根深蒂固:
当你在 Zed 中编辑 buffer 中的文本且启用了语法高亮时, buffer 中文本内容的快照(snapshot)将会发送到后台线程
在该线程中, 使用 tree-sitter 重新解析
每次编辑都会发生, 而且非常非常非常快速高效, 因为快照不需要文本的完整副本, 所需要的仅仅是增加引用计数而已
因为 Zed 中 rope 节点的引用计数是通过 Arc 实现的, Arc 是 rust 中的 "线程安全的引用计数指针"
这就引出了最重要的一点: Zed 中对 rope 的具体实现
因为其实现并不像你在 wiki 上看见的经典 rope 那样, 该实现也为 Zed 中的 rope 提供了其他 rope 可能没有的某些属性
而这种实现, 实际上是使 rope 优先于其他数据结构的原因
引入SumTree
Zed 中的 rope 不是经典的二叉树形式的 rope, 而是一个 sumtree
当你打开 Zed 中关于 Rope 的定义, 你会发现它只不过是由一堆 Chunk 组成的 SumTree:
;
Chunk 是一个 ArrayString, 后者来自于 arrayvec), 允许内联存储 String, 而不是存储在堆的其他地方
含义: Chunk 是一堆字符的集合, chunks 则是 SumTree 中的叶子, 其最多包含 (2 * CHUNK_BASE) 个字符
(在 Zed 的发布版本上, CHUNK_BASE 被定义为 64)
那么什么是 SumTree 呢? 当询问 Nathan 时, 他回答道: "SumTree 是 Zed 的灵魂"
当然, 对 SumTree 的技术描述是这样的:
SumTree<T> 是一个 B+ 树
其每个 Leaf 节点都包含多个类型为 T 的项(item), 每个项都含有一个 Summary
其每个 Internal 节点都含有对于其子树中的项的 Summary
以下是匹配的类型定义, 你能在 sum_tree 这个 crate 中找到它们:
;
>,
},
Leaf >,
item_summaries: 2 * TREE_BASE }>,
},
}
所以, 到底什么是 Summary(摘要) 呢? 哈哈, 是你想要的任何东西!
唯一的要求是, 你需要能够将多个 Summary 添加在一起, 以创建 "a sum of summaries":
哦, 我知道你肯定对我翻了个白眼, 所以让我们把它说得具体些
由于 Rope 是一个 SumTree, 并且 SumTree 中的每个项都必须有一个 Summary, 因此以下是与节点关联的 Summary:
SumTree 中的所有节点(Internal & Leaf)都有这样的 Summary, 其包含了有关其子树的信息
Leaf 节点具有 Chunk 的摘要, Internal 节点具有的摘要则是其子节点的摘要的总和(在树中递归向下)
假设我们有以下 5 行文本:
Hello World!
This is
your captain speaking.
Are you
ready for take-off?
如果将其 push 到 Zed 的 A SumTree representing Rope 中, 则 Rope 下的 SumTree 将如下显示(简化过):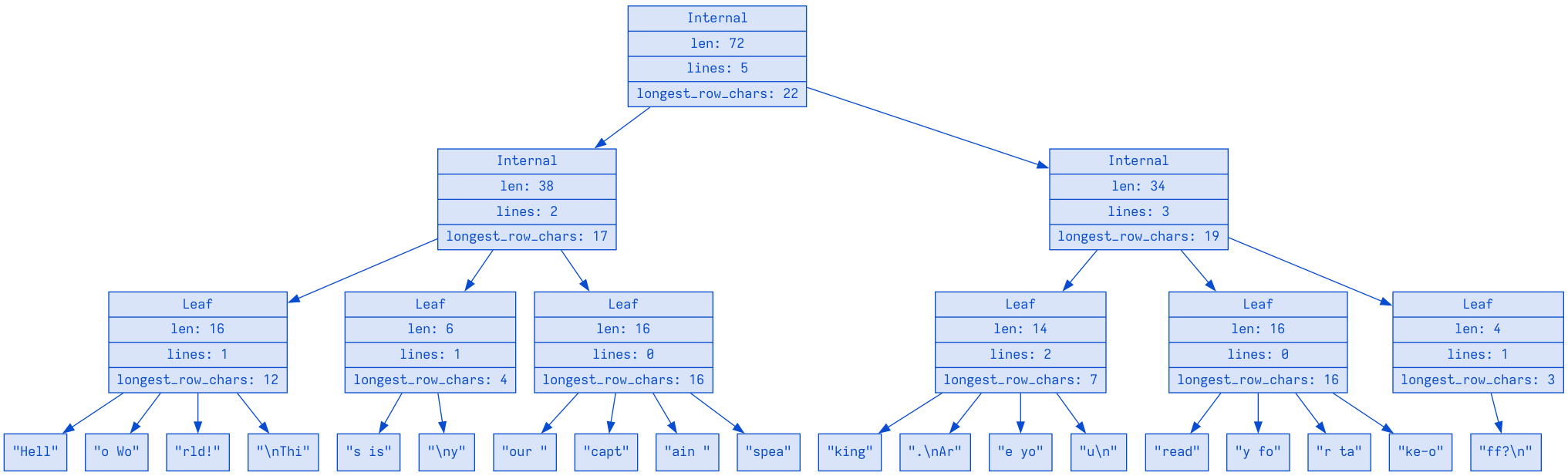
Hello World!\nThis is\nyour captain speaking.\nAre you\nready for take-off?\n with some summary fields left out
我省略了 TextSummary 中的一些字段, 以保持图片较小, 并且调整了 chunks 的最大空间与 每个子节点的最大子项数量
(在 Zed 的发布版本上, 该文本的全部五行适合作为一个节点)
即使只有 3 个摘要字段: len, lines, longest_row_chars, 我们也能看见 Internal 节点的摘要是其子节点的总和
根节点节点的摘要告诉我们完整的文本, 完整的 Rope 的信息: 72 个字符, 5 行, 最长行有 22 个字符("your captain speaking.\n")
而 Interenal 节点则告诉我们关于文本的各个部分的信息, 比如左下的节点说: "Hell" 到 "spea"(包括换行符) 有 38 个字符, 包括 2 个换行符
好吧, 你可能会想, 一个摘要了摘要的 B+ 树, 这给我们带来了什么?
遍历SumTree
SumTree 是一个并发友好的 B树, 为我们提供了一个持久(persistent), 写时复制(copy-on-write)的数据结构去表示文本
同时, 它还通过摘要来索引数据, 允许沿着摘要的维度以 O(log n) 的时间进行遍历
用 Max 的话来讲, SumTree 在概念上并不像一个 map, 而更像一个具有特殊索引功能的 Vec
你可以在其中存储任何所需的 item 的序列, 你决定顺序, 而它提供查找与切片的功能
SumTree 中的 item 是有序的, 它们的摘要也被排序
SumTree 允许你在 O(log N) 的时间内找到树中的任何 item, 方法是从根节点开始遍历, 根据节点的摘要决定访问哪个节点
假设我们有一个 Rope, 里面有 3 行文本:
let mut rope = new;
rope.push;
rope.push;
rope.push;
构造的 A SumTree representing Rope 看起来像这样: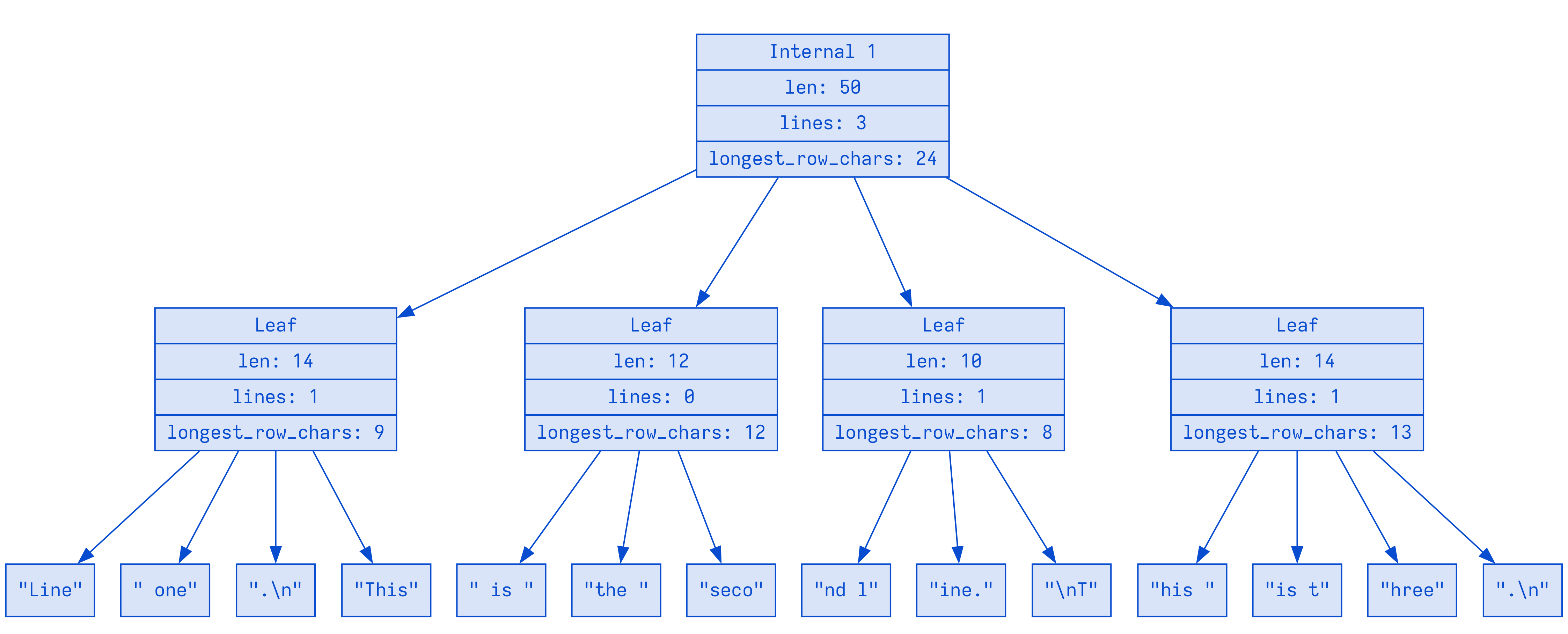
Line one.\nThis is the second line.\nThis is three.\n with some summary fields left out
正如我们上面所说: 每个 Leaf 节点具有多个 Chunk, 且其摘要含有有关 Chunk 中文本的信息
该摘要的类型是上面的 TextSummary, 能告知其 chunks 中文本的长度, 行数, 最长的行, 以及其他所有处于 TextSummary 中的字段
随后, SumTree 中的 Intrnal 节点含有摘要的摘要
由于树中的项(Internal 节点, Leaf 节点, Chunks) 是有序的, 我们可以非常高效地遍历该树, 因为我们可以根据摘要中的值进行遍历
它允许我们沿着单个维度, 比如给定的摘要中的字段, 进行查找
假设我们想知道树中绝对偏移量(absolute offset) 26 处(第26个字符)是什么, 可以沿着 TextSummary 中 len 字段进行遍历
(因为len是从左到右进行增加的, 也就是 absolute offset)
因此, 为了找到这个 absolute offset 26 的位置, 我们遍历树, 取决于 Intrnal 节点的摘要决定左右方向, 直到最终到达满足条件的 Leaf 节点:
let point = rope.offset_to_point;
assert_eq!;
assert_eq!;
从表面看, rope.offset_to_point(26) 将一个 absolute(0-based) 的 offset(即26), 转换为 Point 结构体, 其由 row(行) 与 column(列)组成
该函数内部发生的情况是: cursor 将遍历树, 每次遍历都累计 TextSummary 中的字段 len, 直到找到 >=26 的项
一旦找到第一个 Leaf 节点, 就会找到 offset 匹配的具体 Chunk, 并将 cursor 停在那里
在这个过程中, 它不仅不停地计算遇到的摘要中的 len 字段, 还累计了包含 row 与 column 的 lines 字段, 很整洁, 对吧?
不过在实际代码中, 这是 Rope 上的 offset_to_point 方法:
其作用如下:
- 健全性检查, 检查偏移量是否未超过整个
Rope的行尾 - 创建一个 cursor, 沿着 usize(offset) 与 Point(具有两个字段 row 与 column 的结构体) 的维度进行搜索, 并在执行操作时同时累计两者
- 一旦它在 offset 处找到了项, 就会开始计算 overshoot(过冲, 电子学上指从一个值转换为另一个值时, 参数的瞬时值超过其最终稳态的值):
我们正在寻找的 offset 可能位于单个 chunk 的中间, 且cursor.start().0是一个 usize(offset), 表示给定 chunk 的起始位置 - 取行数至当前 chunk 的起始行 (
cursor.start().1, 即关于当前项左侧的完整的树的TextSummary.len的摘要 - 将它们添加至 offset (可能)位于 chunk 中间部分的行 (
cursor.offset_to_point(overshoot))
这里最有趣的地方在于 self.chunks.cursor::<usize, Point>(), 该 cursor 具有两个维度
它允许您在给定的一个维度(usize)上查找值, 并在同一操作中, 获取特定 cursor 位置的第二个维度(Point)的总和
这样的美妙之处在于其可以在 O(log N) 的时间内完成此操作, 因为每个 Internal 节点都包含摘要的摘要(本例中为所有子项的总 len )
并且可以跳过 len < 26 的所有项 (上图中, 甚至不必去遍历前两个 Leaf 节点)
这不是很神奇吗? 还有更多
使用 SumTree
你也可以反过来遍历 SumTree, 沿着 lines/rows 查找并获取最终的偏移量:
// Go from offset to point:
let point = rope.offset_to_point;
assert_eq!;
assert_eq!;
// Go from point to offset:
let offset = rope.point_to_offset;
assert_eq!;
而且, 你可能猜到了, point_to_offset 与 offset_to_point 看起来一模一样, 仅仅只是构造 cursor 的维度是翻转的:
这种沿着一个或多个维度的累计(概要!)是通过一些 非常聪明的rust代码 实现的, 我不会详细介绍, 但简单版本是这样的:
给定如下所示的 TextSummary(我们在上面已经完整看过了), 与一个包装它的 ChunkSummary:
我们可以将 len 与 lines 字段定义为 sum_tree::Dimensions:
随后, 我们可以通过给定的 sum_tree::D 或一个关于维度的元组(Tuple) 来 构造cursor(这就是我们上面对 (usize, Point) 所做的)
构造完成后, cursor 可以沿着我们定义的任何 Dimension 进行搜索, 并聚合/累计完整的 TextSummary 或给定摘要类型的单个 Dimension
或者我们也可以沿着单个维度搜索, 然后在 cursor 找到目标后获取整个摘要:
let mut rope = new;
rope.push;
rope.push;
rope.push;
// Construct cursor:
let mut cursor = rope.cursor;
// Seek it to offset 55 and get the `TextSummary` at that offset:
let summary = cursor.;
assert_eq!;
assert_eq!;
assert_eq!;
cursor 停在了第 2 行的中间, 第 6 列, 直到该 offset 的位置, 其摘要中的 longest_row_chars 为 24
这是非常强大的东西, 让我们可以轻松在 UTF-8 或 UTF-16 的 (rows, columns) 之间互转
这在使用 LSP(Language Server Protocal) 有时是 必需 的
查找 UTF8 的 Point 并 聚合/累计 UTF16 的 Point:
还有许多......我可以不停地展示更多例子, 或者使用像 monoid homomorphism 这样的大词, 但我就到此为止了
你明白了: SumTree 是一个线程安全, 快照友好, 写入时复制的 B+ 树, 它非常强大, 灵活, 可以不仅仅只是用于文本
这是它在 Zed 中无处不在的原因, 是的, 字面意思
一切都是SumTree
目前, SumTree 在 Zed 中有 20 多种用途, 其不仅用作 Rope 的基础, 而且用于许多不同的地方
项目中的文件列表是一个 SumTree, git blame 返回的信息存储在 SumTree 中, 聊天频道的消息, 还有代码诊断等等......
Zed 的核心是一个名为 DisplayMap 的数据结构, 它包含有关给定文本的 buffer 该如何显示的所有信息: 折叠的位置, 换行的位置, inlay-hints(嵌入提示)的显示位置等:
你猜怎么着? 所有这些后台都使用了 SumTree, 在以后的文章中, 我们将探讨它们, 但我现在想说的是:
Zed 的联合创始人们并没有决定在 gap-buffer 或 piece-table 上使用 rope
而是从 SumTree 开始, 认识到它有多么强大, 如何满足 Zed 的要求, 然后基于它构造了 Rope
rope 可能是 Zed 的心脏, 但 SumTree 是, 再次引用 Nathan 的话, 是 "Zed 的灵魂"
The rope may be at the heart of Zed, but the SumTree is, to quote Nathan again, "the soul of Zed".
